Oracle 23ai - Models and Embeddings - Part 1
Exploring the new suite of AI-centric features in Oracle 23ai - part 1


A Tale of Two Approaches
My journey into machine learning has always been driven by a simple principle: the best way to learn is to build. Doing a Recommendation System (like Netflix recommending a movie) is something that I wanted to do for a while. The release of Oracle Database 23ai and its new suite of AI-centric features looks like an interesting time to explore what parts of a Data Science project can now be done directly in 23ai versus in a Python environment.
In particular, the introduction of AI Vector Search and native support for running ONNX machine learning models directly in the database seemed like a game-changer. This felt like the perfect project: could I build a movie recommender that leverages these powerful new capabilities?
Note: Part 2 is now available.
This post is the first in a two-part series detailing that journey. Our goal in this first Post is to build a baseline movie recommender and explore two different ways to do it:
- The traditional data scientist's way in Python
- The Oracle 23ai way, performing the exact same task without ever leaving the database.
All the source code is available in my GitHub repo.
Key Insights:
- 📦 Oracle 23ai has pre-configured Text Embedding Models that can be loaded directly into the database
- 🔍 Oracle 23ai AI Vector Search allows to find similar entities, expressed as Embeddings
- 🐍 Some typical Python Data Science workflows (Out-of-Database) can now be done directly in an Oracle 23ai database (In-Database)
The Data Scientist's Approach: With Python
First, we try an Out-of-Database approach.
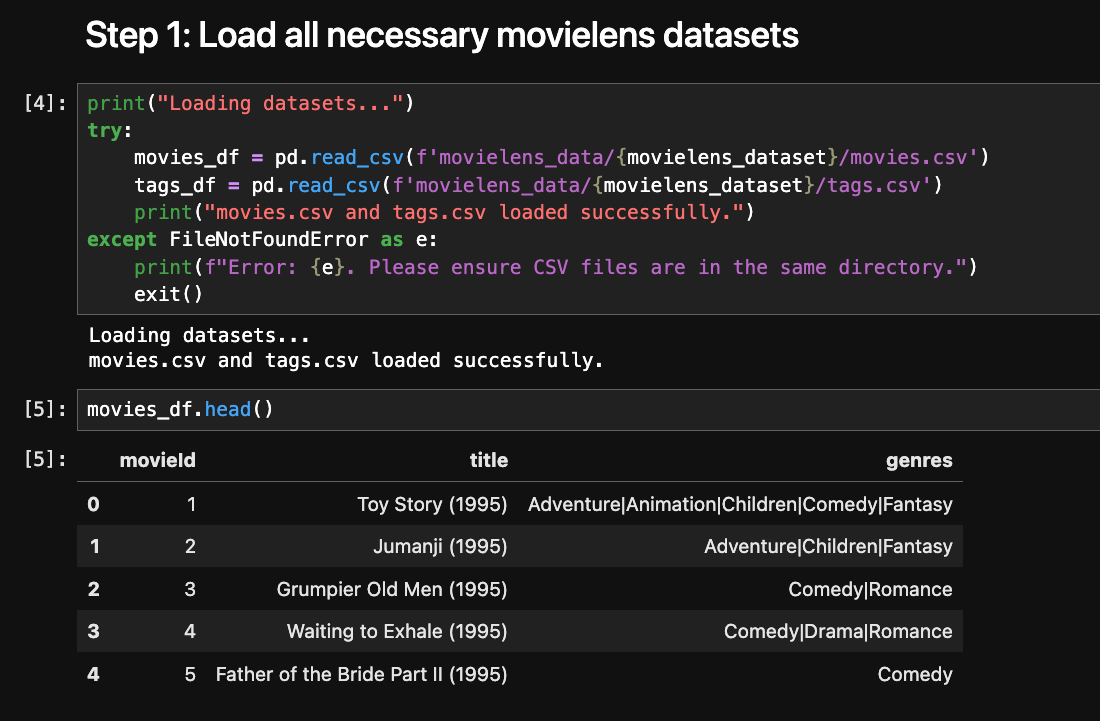
Every recommendation project needs data. For this, we'll turn to a classic Movie Dataset.
Our Dataset: MovieLens
The MovieLens dataset is a stable, well-regarded dataset containing movie information and user ratings. To really test the performance, I decided to use the "Full" 32M dataset, which includes over 32 million ratings for nearly 88,000 movies. As we'll see, even this large dataset is handled with ease by an Always Free Autonomous Database instance.
Note: This large Movielens dataset is still a subset of what is used on their website.
The Core Concept: Embeddings
The core idea of our recommender is to find movies that are "semantically similar." But how does a computer understand the "meaning" of a movie like "Inception"? The answer is embeddings.
An embedding is a vector (think a list) of numbers that represents an object like a movie, a word, or an image. Movies with similar meanings will have vectors that are "close" to each other in mathematical space.
A bit of Math: Just like a point in a 2D space is defined by its 2 coordinates (x, y), a point in a 384 dimensions space will be defined by its 384 coordinates that we call a vector.
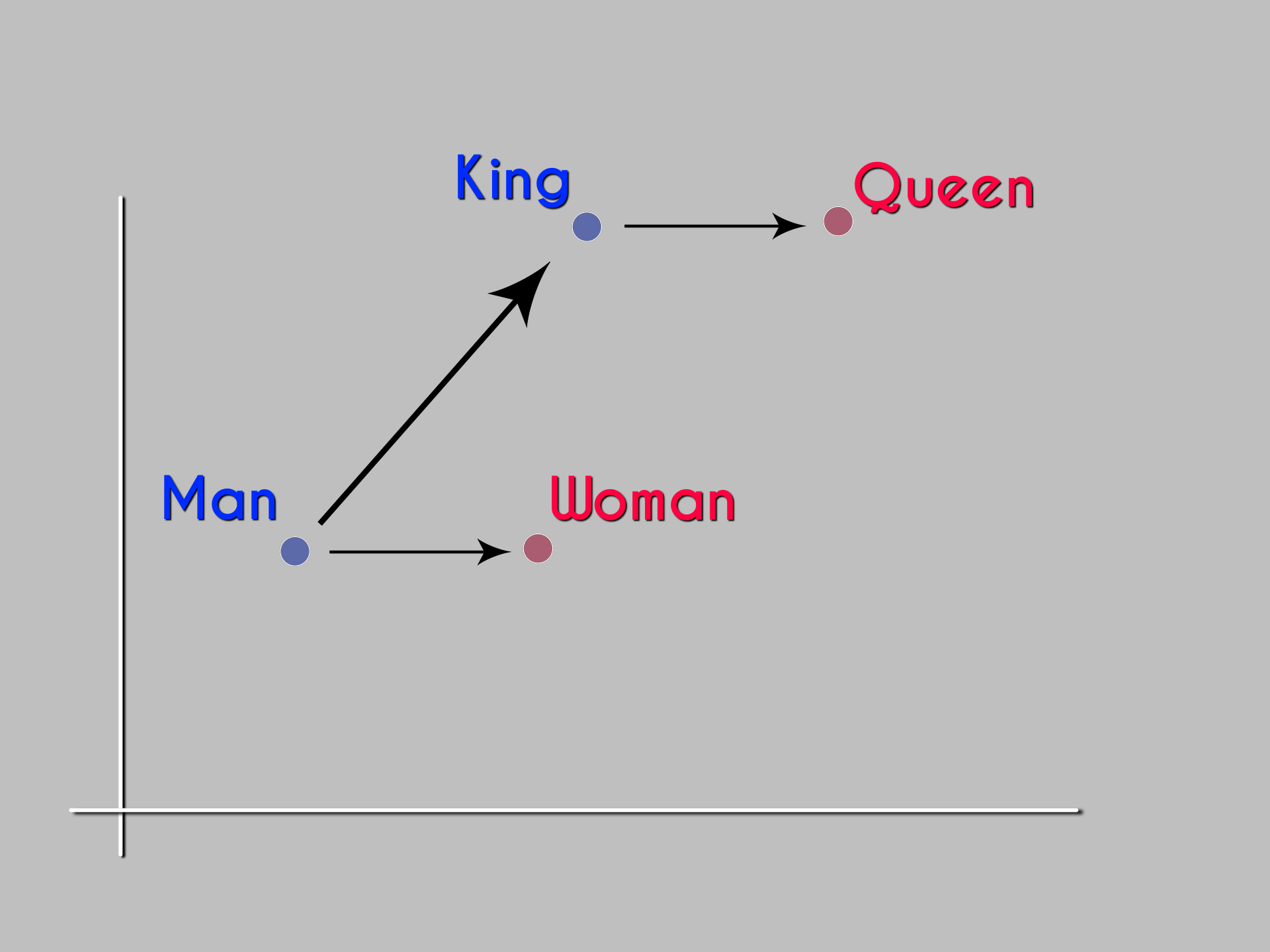
So the magic is that objects with similar meanings will have vectors that are mathematically close to each other. The classic illustration is vector(King) - vector(Man) + vector(Woman), which results in a vector very close to vector(Queen). We want to do the same for movies.
Generating Embeddings with Python
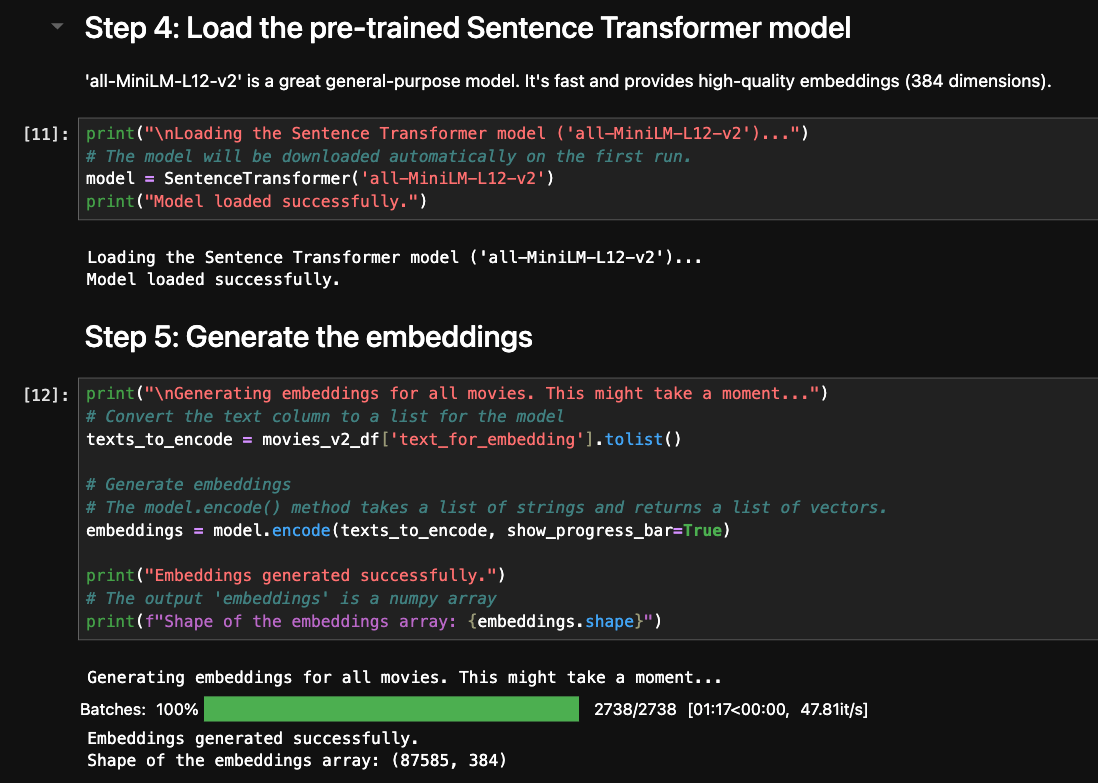
Our strategy is to create a text description for each movie by using information about the movie. Then, we can use a pre-trained language model to convert this text into an embedding. For this task, I chose all-MiniLM-L12-v2, a powerful 12-layer model from the sentence-transformers library.
The main steps are shown below. You can also look at the full Jupyter notebook.
So for each movie, we generate a string that contains:
- The title
- The year
- The genres
- The user-generated tags
Our experiment here is to determine if this whole string can capture the essence of the movie.
For example, for the movie Inception, the generated string would be (partial):
Title: Inception (2010). Genres: Action, Crime, Drama, Mystery, Sci-Fi, Thriller, IMAX. Tags: action, dream within a dream, dreamlike, Leonardo DiCaprio, multiple interpretations, surreal, Tokyo, visually appealing, alternate reality, cerebral, Christopher Nolan, complex, complicated, dreams, editing, ensemble cast, great cast, Hans Zimmer, heist, intellectual, intense, ... From Texts to Embeddings
The Results: A First Look
With the embeddings generated, we can now pick a movie and find its nearest neighbors using cosine similarity. I tested five movies to see how well this content-based approach captured their "vibe".
--------------------------------------------------
Finding top 5 similar movies for: 'Apocalypse Now (1979)'
- [REC] 4: Apocalypse (2014) (Similarity: 0.6855)
- The Apocalypse (1997) (Similarity: 0.6747)
- X-Men: Apocalypse (2016) (Similarity: 0.6577)
- LA Apocalypse (2014) (Similarity: 0.6536)
- Music and Apocalypse (2019) (Similarity: 0.6533)
--------------------------------------------------
--------------------------------------------------
Finding top 5 similar movies for: 'Inception (2010)'
- The Edge of Dreaming (2010) (Similarity: 0.6904)
- 2012: An Awakening (2009) (Similarity: 0.6797)
- Dreams Awake (2011) (Similarity: 0.6792)
- Dead Awake (2010) (Similarity: 0.6685)
- Locked In (2010) (Similarity: 0.6513)
--------------------------------------------------
--------------------------------------------------
Finding top 5 similar movies for: 'Arrival (2016)'
- Arrival, The (1996) (Similarity: 0.7140)
- Approaching the Unknown (2016) (Similarity: 0.6965)
- The Arrival (2017) (Similarity: 0.6893)
- Alien Expedition (2018) (Similarity: 0.6681)
- Conspiracy Encounters (2016) (Similarity: 0.6620)
--------------------------------------------------
--------------------------------------------------
Finding top 5 similar movies for: 'My Life as a Dog (Mitt liv som hund) (1985)'
- It's a Dog's Life (1955) (Similarity: 0.6940)
- Dog Tags (1985) (Similarity: 0.6809)
- Dog (2017) (Similarity: 0.6769)
- Dog (2022) (Similarity: 0.6628)
- Year of the Dog (2007) (Similarity: 0.6467)
--------------------------------------------------
--------------------------------------------------
Finding top 5 similar movies for: 'Other Guys, The (2010)'
- Good Guy, The (2009) (Similarity: 0.6641)
- The External World (2010) (Similarity: 0.6542)
- Extra Man, The (2010) (Similarity: 0.6523)
- Multi Release Movements (2010) (Similarity: 0.6512)
- Date Night (2010) (Similarity: 0.6368)
--------------------------------------------------
The results are a mixed bag at best. For a movie like 'Inception (2010)', we see that the Tags helped refer to dreaming, but it's not much more subtle than that. For 'My Life as a Dog (1985)', a coming-of-age drama, the model recommended movies like 'A Dog's Purpose' and 'Dog Days'. It completely missed the metaphorical "vibe" and latched onto the literal keyword "Dog".
This is a classic limitation of content-based filtering, which often struggles with nuance and metaphor, a problem we will explore and solve in Part 2.
But this is a blog series about Oracle 23ai, right? So let's see how we can achieve the exact same result, but by doing our data science directly inside the database.
The Oracle 23ai's Approach: All in the Database
The Python approach works, but it requires managing a separate environment and may require moving data out of the database. What if we could achieve the same result natively in Oracle?
Thanks to Oracle 23ai, we can do an In-Database approach.
Preparation
First, I set up an Always Free Autonomous Database instance on OCI and loaded my raw movies and tags data (movies.csv and tags.csv) into tables.
Is an Always Free Autonomous Database strong enough to host models, embeddings, and all our data? Yes, it will eat that for breakfast without breaking a sweat.
Creating Tables
CREATE TABLE MOVIES (
MOVIEID NUMBER PRIMARY KEY,
TITLE VARCHAR2(255) NOT NULL,
GENRES VARCHAR2(255)
);
CREATE TABLE TAGS (
USERID NUMBER,
MOVIEID NUMBER,
TAG VARCHAR2(255),
TIMESTAMP number
);Movie table loaded - about 87,500 rows
Tags table loaded - about 2,000,000 rows
Preparing the Tags string into text_for_embedding1
Once the movielens csv files are loaded in the movies and tags tables, let's add 2 columns to contain:
- The full text to embed
- The
all-MiniLM-L12-v2embedding itself
ALTER TABLE movies ADD (
text_for_embedding1 CLOB, -- The text used to create the embedding
movie_embedding1 VECTOR(384, FLOAT32) -- The embedding itself
);
We can now fill text_for_embedding1 with the Title, Genres and Tags in a way that is equivalent to what we did in Python with:
MERGE INTO movies m
USING (
WITH
aggregated_tags AS (
SELECT
movieId,
-- LISTAGG does the aggregation
LISTAGG(DISTINCT tag, ', ') WITHIN GROUP (ORDER BY tag) AS tag_list
FROM
TAGS
GROUP BY
movieId
)
SELECT
m.movieId,
'Title: ' || m.title ||
'. Genres: ' || REPLACE(m.genres, '|', ', ') ||
'. Tags: ' || NVL(t.tag_list, '')
AS final_text
FROM
MOVIES m
LEFT JOIN aggregated_tags t ON m.movieId = t.movieId
) source_query
ON (m.movieId = source_query.movieId)
WHEN MATCHED THEN
UPDATE SET m.text_for_embedding1 = source_query.final_text;
You should receive something like
87,585 rows merged.
Elapsed: 00:00:08.891
Note about the power of LISTAGG: This single SQL statement replaces multiple steps in Python (likegroupby,unique, andjoin) and does the work efficiently on the database, right next to the data.
With text_for_embedding1 filled, the movies table will look like:
In-Database Embeddings with a Pre-Built ONNX Model
This is where the magic happens. The Oracle Machine Learning team has provided a pre-built, augmented version of the very same all-MiniLM-L12-v2 model in the ONNX (Open Neural Network Exchange) format, ready to be deployed in the database.
Note about "ready to be deployed": Text embedding models need some pre-processing and post-processing to be "ready to be deployed" in Oracle 23ai, see this page for more information.
First, I loaded this ONNX model into the database using a PL/SQL block
DECLARE
ONNX_MOD_FILE VARCHAR2(100) := 'all_MiniLM_L12_v2.onnx';
MODNAME VARCHAR2(500);
LOCATION_URI VARCHAR2(200) := 'https://adwc4pm.objectstorage.us-ashburn-1.oci.customer-oci.com/p/eLddQappgBJ7jNi6Guz9m9LOtYe2u8LWY19GfgU8flFK4N9YgP4kTlrE9Px3pE12/n/adwc4pm/b/OML-Resources/o/';
BEGIN
DBMS_OUTPUT.PUT_LINE('ONNX model file name in Object Storage is: '||ONNX_MOD_FILE);
--------------------------------------------
-- Define a model name for the loaded model
--------------------------------------------
SELECT UPPER(REGEXP_SUBSTR(ONNX_MOD_FILE, '[^.]+')) INTO MODNAME;
DBMS_OUTPUT.PUT_LINE('Model will be loaded and saved with name: '||MODNAME);
-----------------------------------------
-- Load the ONNX model to the database
-----------------------------------------
DBMS_VECTOR.LOAD_ONNX_MODEL_CLOUD(
model_name => MODNAME,
credential => NULL,
uri => LOCATION_URI || ONNX_MOD_FILE,
metadata => JSON('{"function" : "embedding", "embeddingOutput" : "embedding" , "input": {"input": ["DATA"]}}')
);
DBMS_OUTPUT.PUT_LINE('New model successfully loaded with name: '||MODNAME);
END;
Note about the code above: This is a simplification of this code that worked better for me, solving issues with the DBMS_CLOUD.GET_OBJECT().
Once the model was loaded, I could use it directly in SQL with the new VECTOR_EMBEDDING() function to generate embeddings for all 87,585 movies and store them in a VECTOR data type column.
This PL/SQL code will generate an embedding for every movie in the table.
It will take several minutes to run on the full dataset as it calls the ONNX model for each row.
DECLARE
-- Define the size of each batch
CHUNK_SIZE NUMBER := 1000;
-- Define a collection type to hold a batch of movie IDs
TYPE movie_id_list IS TABLE OF movies.movieId%TYPE;
-- Declare a variable of our collection type
l_movie_ids movie_id_list;
-- Define a cursor to select all movies that still need an embedding
CURSOR c_movies_to_process IS
SELECT movieId
FROM movies
WHERE movie_embedding1 IS NULL;
BEGIN
DBMS_OUTPUT.PUT_LINE('Starting batch embedding generation...');
OPEN c_movies_to_process;
LOOP
-- Fetch a "chunk" of movie IDs into our collection variable
FETCH c_movies_to_process
BULK COLLECT INTO l_movie_ids
LIMIT CHUNK_SIZE;
-- Exit the loop if there are no more rows to process
EXIT WHEN l_movie_ids.COUNT = 0;
DBMS_OUTPUT.PUT_LINE('Processing ' || l_movie_ids.COUNT || ' movies...');
-- FORALL is faster than a standard loop.
FORALL i IN 1 .. l_movie_ids.COUNT
UPDATE movies
SET movie_embedding1 = VECTOR_EMBEDDING(
ALL_MINILM_L12_V2 -- Use the name you gave the ONNX model
USING text_for_embedding1 AS data
)
WHERE movieId = l_movie_ids(i);
-- Commit the changes for this chunk to the database
COMMIT;
DBMS_OUTPUT.PUT_LINE(' ... Chunk committed.');
END LOOP;
CLOSE c_movies_to_process;
DBMS_OUTPUT.PUT_LINE('Batch embedding generation complete.');
EXCEPTION
WHEN OTHERS THEN
-- Close the cursor if an error occurs
IF c_movies_to_process%ISOPEN THEN
CLOSE c_movies_to_process;
END IF;
-- Re-raise the exception so you can see the error message
RAISE;
END;
We can now see the Embeddings (384 numbers) for each movie in MOVIE_EMBEDDINGS1
Finding similar movies with Oracle 23ai
With the embeddings now generated and stored natively, I ran the same similarity search as before, this time using the VECTOR_DISTANCE SQL function.
To find movies that are similar to our 5 movies, I used:
WITH
-- Step 1: Define the 5 movie titles we want to find recommendations for.
source_movies AS (
SELECT 'Apocalypse Now (1979)' AS title UNION ALL
SELECT 'Inception (2010)' AS title UNION ALL
SELECT 'Arrival (2016)' AS title UNION ALL
SELECT 'My Life as a Dog (Mitt liv som hund) (1985)' AS title UNION ALL
SELECT 'Other Guys, The (2010)' AS title
),
-- Step 2: Calculate the cosine distance between our 5 source movies
-- and every other movie in the main 'movies' table.
similarity_scores AS (
SELECT
s.title AS source_title,
c.title AS candidate_title,
-- Use the VECTOR_DISTANCE function on our new in-database embeddings
VECTOR_DISTANCE(s_emb.movie_embedding1, c.movie_embedding1, COSINE) AS distance
FROM
source_movies s
-- Join to get the embedding for our source movies
JOIN movies s_emb ON s.title = s_emb.title
-- Cross join to compare with every candidate movie in the catalog
CROSS JOIN movies c
WHERE
s.title != c.title -- Ensure we don't compare a movie to itself
),
-- Step 3: Rank the results for each source movie independently.
ranked_similarities AS (
SELECT
source_title,
candidate_title,
distance,
-- The ROW_NUMBER() analytic function assigns a rank based on the distance.
-- PARTITION BY source_title means the ranking (1, 2, 3...) restarts for each source movie.
ROW_NUMBER() OVER (PARTITION BY source_title ORDER BY distance ASC) as rnk
FROM
similarity_scores
)
-- Step 4: Select only the top 5 recommendations (where rank is 1 through 5) for each movie.
SELECT
source_title,
candidate_title,
distance
FROM
ranked_similarities
WHERE
rnk <= 5
ORDER BY
source_title,
rnk;
Comparing Oracle 23ai with Python
Let's compare the Oracle 23ai results with the previous recommendations in Python
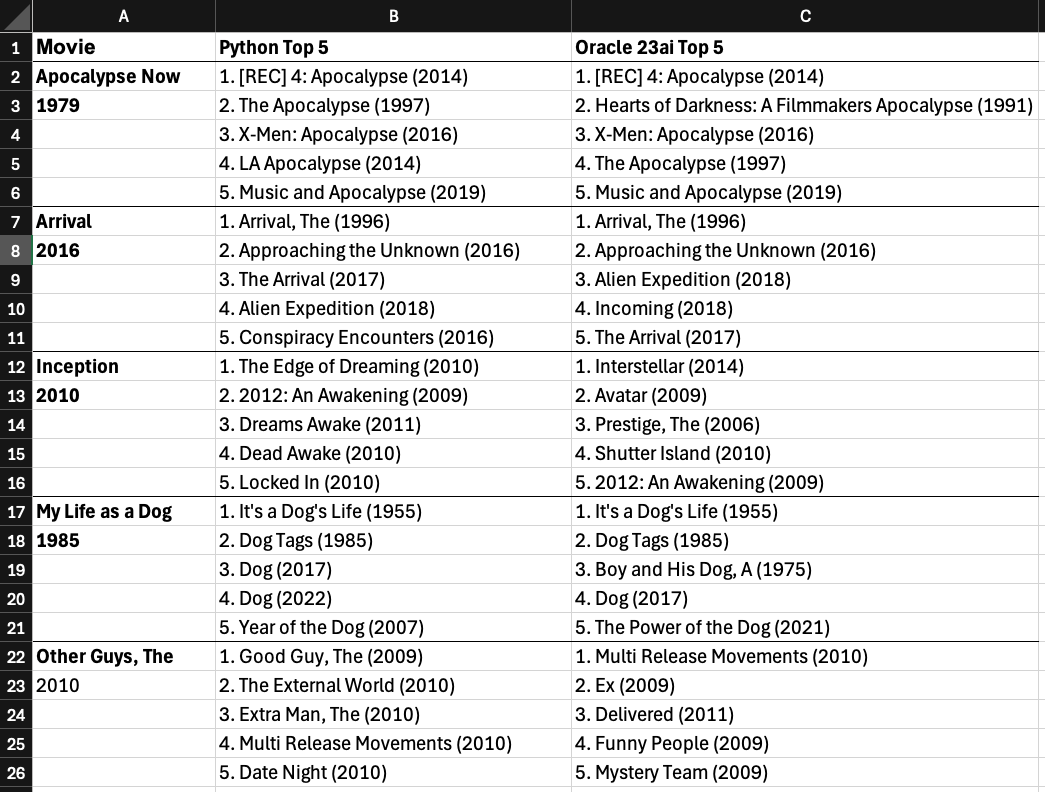
The results were similar to the Python approach, including the same flawed "dog movie" recommendations for 'My Life as a Dog', and 'X-Men: Apocalypse' for 'Apocalypse Now'.
As expected, it proves that Oracle 23ai can now perform these powerful embedding generation tasks directly in the database with a simple SQL interface, achieving parity for some external Python data science workflows.
Actually, it appears that the pre-built ALL_MINILM_L12_V2 model that Oracle provides might be a bit better, in particular for the movie Inception. Interesting...
Conclusion and What's Next
In this post, we built a complete content-based recommender system in two different ways. We saw that whether you use Python or native SQL with Oracle 23ai, you can easily turn texts into powerful embedding vectors for similarity search. We also confirmed a fundamental truth: this simple approach is a great start, but it often fails to capture the true "vibe" of the content.
To get better recommendations, we need a better model.
In Part 2 of this series, we will tackle this problem head-on. I will show you how to build a superior, custom Collaborative Filtering recommender model that learns from user behavior. Then, we will walk through the entire process of packaging that custom model and deploying it into our Oracle 23ai database. Stay tuned!



