My Journey through the new Machine Learning Specialization from DeepLearning.AI
My Journey through the new Machine Learning Specialization from DeepLearning.AI


1. Introduction: Revisiting the Fundamentals
Back in 2018, I took Andrew Ng’s original Machine Learning course on Coursera. It was the course that truly kickstarted my path to knowledge in this field, a journey I've written about before. In the years since, I have taken many other ML courses and applied these concepts in the real world, including building deep learning models for my own mobile application.
So, you might ask, why go back and take a foundational course again in April to June 2025?
The reason is simple: To see if this was still the right starting point I could confidently recommend to others.
I decided to enroll in the new Machine Learning Specialization from DeepLearning.AI and Stanford Online. It's a completely revamped version of the classic course.
This post is a summary of that journey. I’ll walk through what the specialization covers, how it feels to learn from a master teacher, and my personal tips for getting the most out of it.
2. The Teacher: Andrew Ng's Masterclass in Pedagogy
If I were to list the best professors I've ever had, Andrew Ng would be near the top. Going through his material again, I was struck by how deliberately and skillfully it is crafted. His teaching isn't just about knowledge; it's a masterclass in pedagogy.

Three things make his approach so effective:
- Clarity Above All: Every concept, term, and piece of notation is introduced with exceptional clarity. There is no ambiguity.
- Intuition First, Math Second: He builds your intuition with clever analogies. You may have heard of the "bowl of soup" or "hammock" shape to explain what a convex function is—a key idea for finding the "lowest point" in a model's error. These mental pictures help make the later math feel natural rather than intimidating.
- A Step-by-Step Stairway: The curriculum is built in small, logical steps. Each new concept rests firmly on the previous one, making the climb feel manageable and relatively easy.
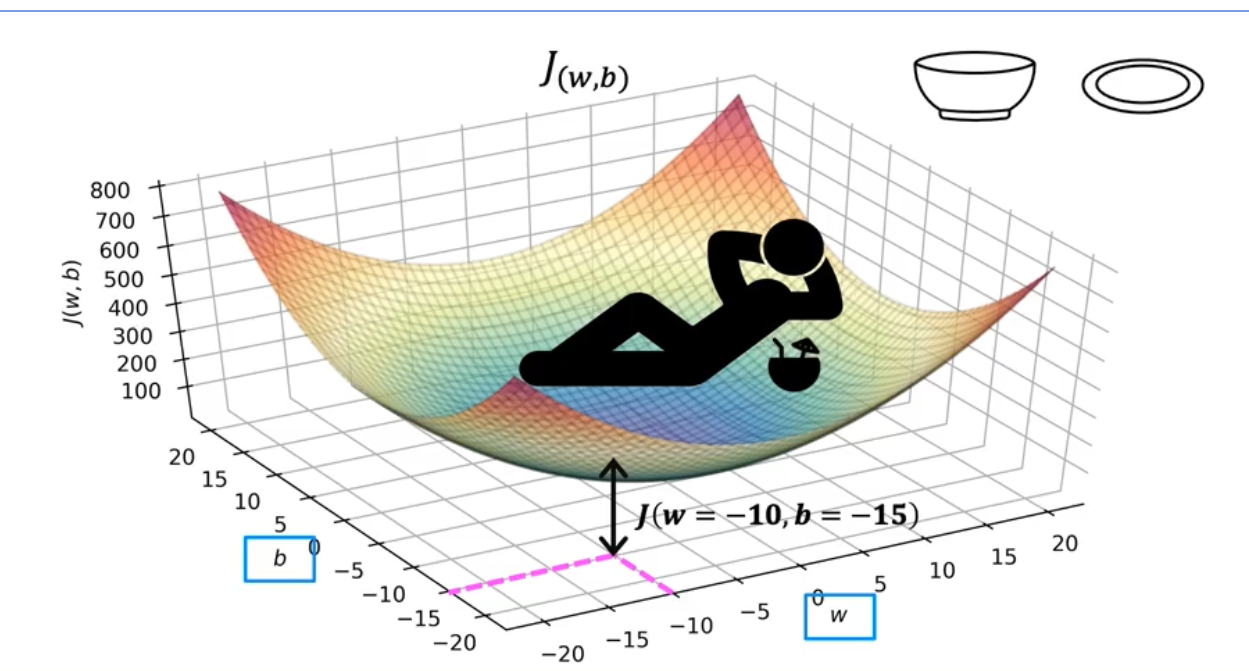
His presentation style is also remarkable. The slides are clean, well crafted, and perfectly synchronized with his explanations, focusing your attention on exactly what matters at that moment. For anyone who wants to learn how to teach a complex subject, this course is as much a lesson in that as it is in machine learning.
3. Specialization Content: What It Covers
The specialization is broken down into three courses. A great thing about the structure is that each new topic is generally presented in a consistent order:
- Building Intuition: An easy-to-understand, high-level explanation.
- The Math: The formal equations and notation behind the concept.
- Code & Labs: Quizzes and hands-on programming assignments in Jupyter Notebooks to solidify your understanding.
This new version uses Python and numpy, which is the standard in the industry today and a huge improvement from the Octave/MATLAB used in the old course.
I am not going into any details here. The specialization does that well. This is to give you a taste of what to expect.
Course 1: Supervised Machine Learning: Regression and Classification
This course lays the groundwork for everything that follows. It starts with the most fundamental building block of many models, a simple linear equation:
Y=WX+b
It might look like simple high school math, but understanding the W (weight) and b (bias) here is key. These are the first two parameters you learn to train. This concept scales all the way up to today's large language models, which are essentially doing the same thing but with billions of parameters. Starting with just two makes the process understandable.
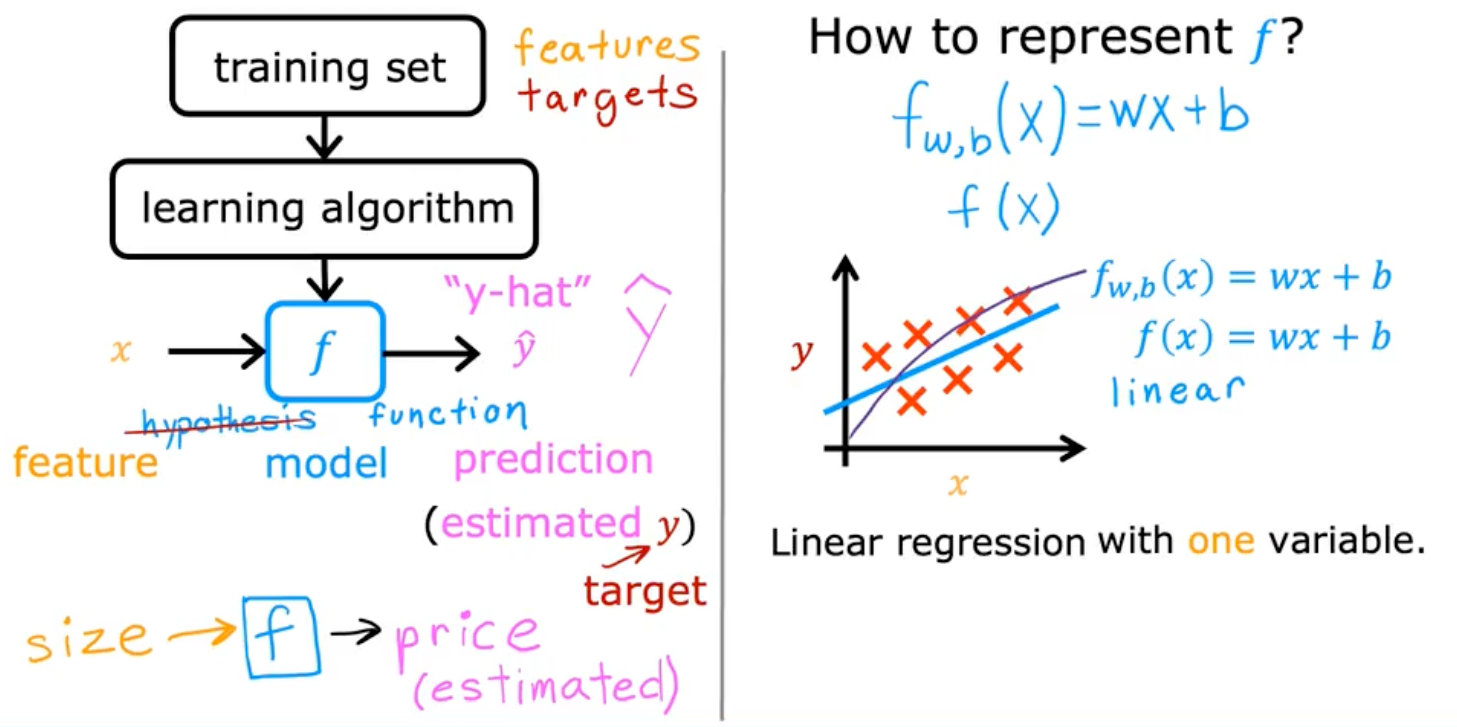
- Week 1: Introduction to Machine Learning. You learn to differentiate between supervised learning (learning from labeled data, like pictures of cats and dogs) and unsupervised learning (finding patterns in unlabeled data). You get comfortable with the Jupyter Notebook environment and build your first linear regression model.
In supervised learning, problems typically fall into one of two main camps: classification or regression. A classification problem involves predicting a distinct category or label; for instance, training a model to look at an image and decide if it is a 'cat' or a 'dog'. In contrast, a regression problem is about predicting a continuous numerical value, like estimating the price of a house, which could be $450,000 or $900,000.
- Week 2: Regression with Multiple Input Variables. This week is about making your models better. You learn how to use multiple inputs (e.g., predicting a house price from its size, number of bedrooms, and age). You also learn about essential techniques that help the model train faster and more effectively. This is where you'll get your hands dirty with NumPy, which is a super, super important library for any ML practitioner. The first graded coding exercise is at the end of this week. The math equations might look scary at first, but if you take it one step at a time, it's very manageable.
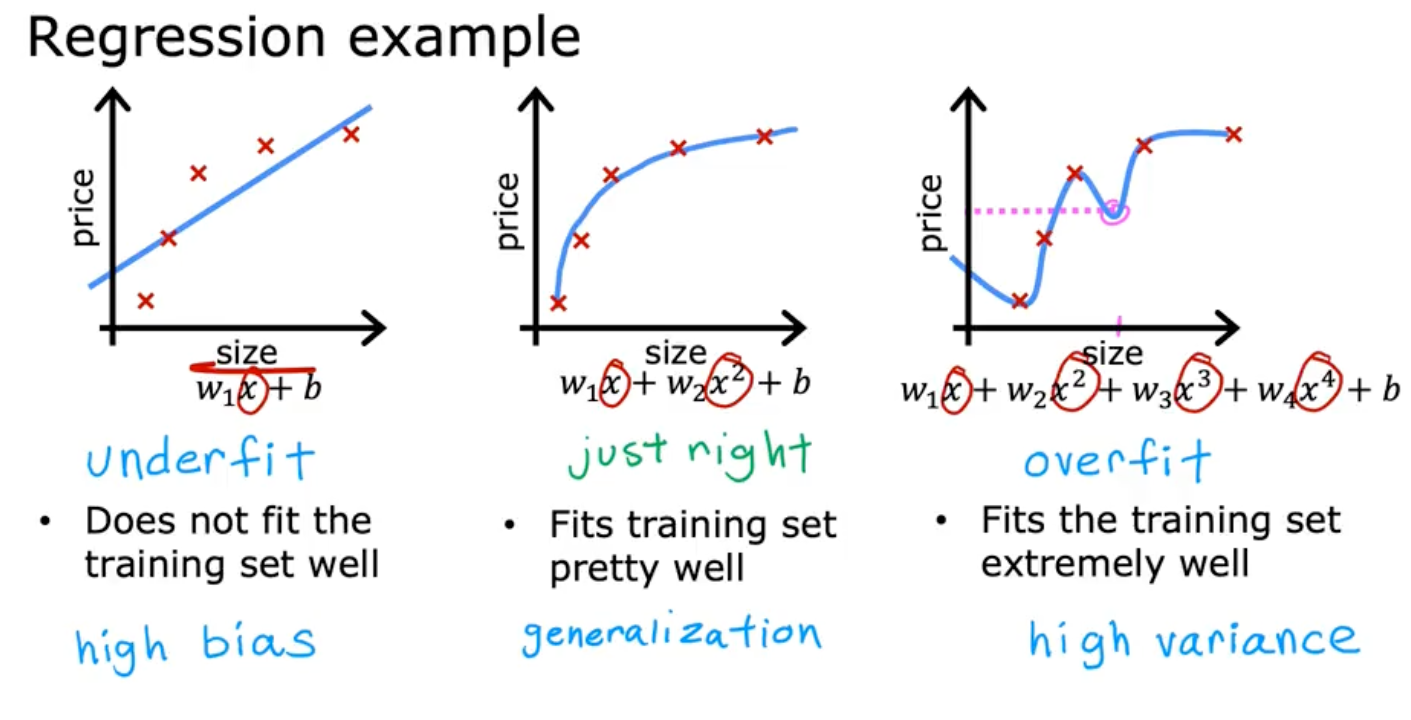
- Week 3: Classification. Here, you shift from predicting numbers (regression) to predicting categories (classification). The main algorithm introduced is logistic regression—which, despite its name, is used for classification problems like determining if an email is spam or not spam. Most importantly, this week introduces the concept of overfitting. This is when a model performs perfectly on the training data but fails on new, unseen data because it has essentially "memorized the answers" instead of learning the underlying pattern. You learn techniques to prevent this, which is a critical skill for building models that work in the real world.
Course 2: Advanced Learning Algorithms
After building the foundation in Course 1, this second course takes you deeper into more powerful models. It covers the theory and practice of neural networks and decision trees, but just as importantly, it provides a ton of practical advice on how to be a good machine learning practitioner.
- Week 1: Neural Networks. This is where you start building more complex models that can learn their own features from data. As Andrew Ng puts it, instead of you needing to manually engineer features, the neural network learns them itself. You start by learning the components—nodes and layers—and build one from scratch in Python. I have to say, there is nothing like suffering a bit by coding it all by hand to truly understand how a neural network works. But right after that, you get to do the same thing in just a few lines of code using TensorFlow, a popular Deep Learning framework. Andrew Ng makes a great point here for beginners who might feel like impostors after writing five lines of code to build a simple model: he actually takes the time to explain what those five lines are doing.
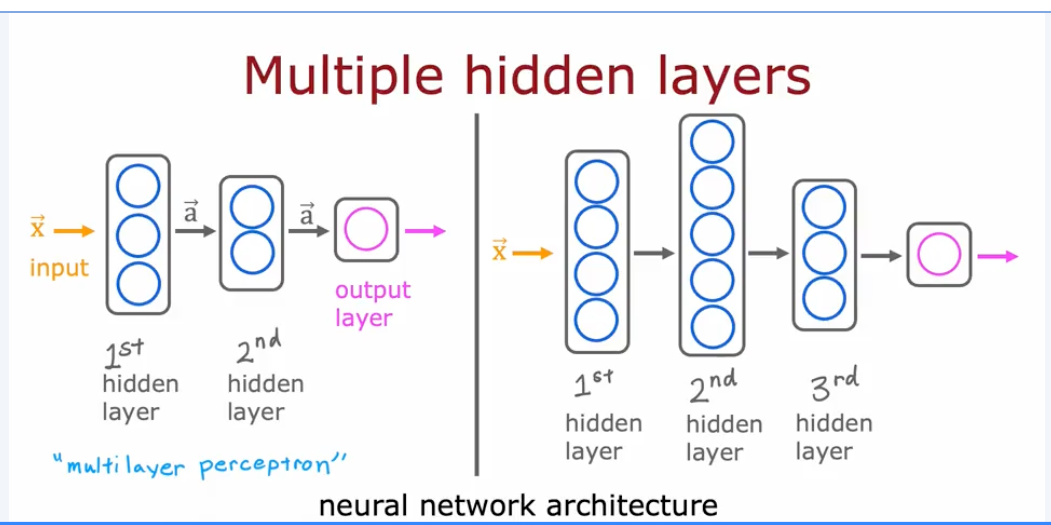
- Week 2: Neural Network Training. This week focuses on the practicals of training your neural network using TensorFlow. You learn about important concepts like "loss functions," which is just a way to measure how wrong your model's predictions are. Don't worry if you see intimidating terms like "categorical cross-entropy"; Andrew Ng does a great job of clarifying these big terms and making them understandable.
- Week 3: Advices for Applying Machine Learning. For me, this week was one of the most valuable parts of the entire specialization. It's packed with practical methodologies that separate a novice from a professional. You learn the iterative loop of ML development and how to diagnose if your model is suffering from bias or variance (I prefer the terms underfit and overfit). Crucially, you learn about the importance of setting aside data for validation and testing, and the process of error analysis—looking at the examples your model gets wrong to figure out how to improve it. Over the years, I have found this to be one of the most critical skills for improving a model in the real world.
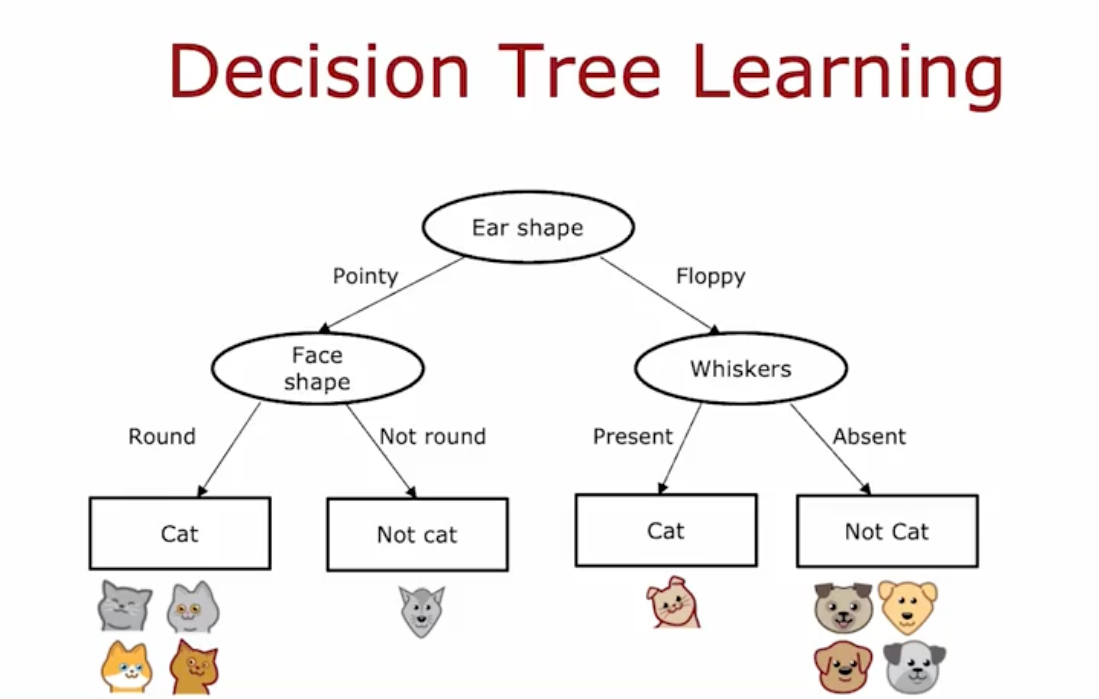
- Week 4: Decision Trees. The course then shifts to a different but very powerful type of model: the decision tree. These are excellent for working with structured data (like the neat rows and columns you'd find in a database table). You learn how a decision tree makes predictions by asking a series of simple "if/then" questions. The course gives very practical advice on when you should choose a decision tree over a neural network, which is a common question for ML practitioners.
Course 3: Unsupervised Learning, Recommenders, Reinforcement Learning
The final course explores what you can do with data that isn't labeled. This part of the course felt a bit more challenging to me, mainly because I have less hands-on project experience with these specific topics. It was a great opportunity to learn.
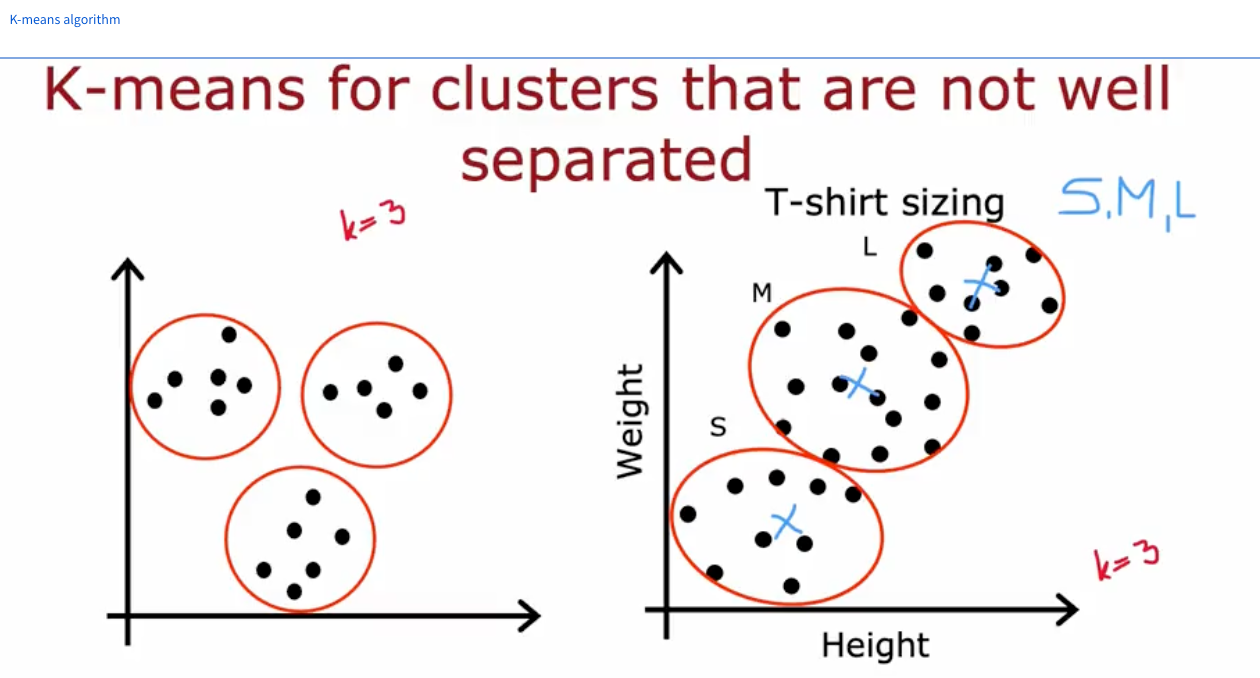
- Week 1: Unsupervised Learning. Here you dive into two main tasks. The first is clustering with the k-means algorithm, which is essentially about finding natural groupings in your data without being told what the groups are. The second is anomaly detection, which is used to identify rare or unusual data points, a technique often used in fraud detection or for finding defects in manufacturing. The examples are presented beautifully on 2D graphs, making the concepts very visual and easy to grasp.
- Week 2: Recommenders. This week demystifies the technology behind systems like Netflix movie recommendations. You learn how to build recommender systems using two main approaches: collaborative filtering (i.e., "users who liked what you liked also liked this") and content-based filtering (i.e., "you seem to like movies with this actor, so here's another one"). You build these systems yourself in TensorFlow using the movielens dataset.
- Week 3: Reinforcement Learning. This was a good introduction to a completely different paradigm of machine learning, and it was not part of the original course I took in 2018. As someone who has since taken other courses on Reinforcement Learning (RL), I can say that I would have loved to have this clear and concise introduction before starting that journey. You learn the core concepts of RL—states, actions, rewards—and you end up using a top-notch algorithm (Deep Q-Learning) to train an agent to solve a fun problem: landing a lunar lander in a simulation. It’s a fun conclusion to the specialization.
4. My Tips About Learning in online courses
To get the most out of this specialization—or any online course, really—it helps to be organized and intentional. Over the years, I've developed a few practices that I found very helpful during these learning experiences.
- Organize Your Digital Assets. My most important tip is to save the materials for future use.
- Take Screenshots of the Slides: I take a screenshot of every single slide. This creates a quick, visual reference library that I can search through far more easily than re-watching a video.
- Download and Re-run the Notebooks: If you can, don't just run the labs in the browser. Download all the Jupyter Notebooks and their associated files. Set them up on your own computer. This is the most important step for true learning. These notebooks become the foundation for your own future projects and a personal code library you can always refer back to.
- Save Videos for Tough Spots: For any topic that still feels a bit approximate, download the video. I did this for some of the unsupervised learning material. Being able to re-watch a tricky explanation offline, at your own pace, is precious.
- Find Your Learning Zone. Online courses give you the flexibility to learn when you are at your best. Use it.
- Protect Your Mental Energy: These topics require focus. Make sure you are rested and approach the material when you feel alert and have a "learning attitude." Forcing it when you're tired is far less effective. For me, weekends work best. Find what works for you.
- Learn in Chunks: Learning is often better when done in smaller sessions with time to reflect in between. The specialization is well-structured for this, so you can easily do a few lessons at a time.

- Engage Actively, Don't Just Watch.
- Try to Guess What's Next: One trick I use is to pause and try to guess what the teacher will explain next. When I'm wrong, I know it's a sign to pay closer attention to that part until the concept clicks.
- Apply It to Your Own Ideas: For each new technique, run a thought experiment. How could I use this in a project of my own? It turns out (as Andrew Ng would say) that this habit of connecting concepts to applications is what turns academic knowledge into practical skill.
- At the end of the Machine Learning Specialization, start a mini-project based on your ideas. Important tip: Start small!
- A Quick Note on
numpy: If you are new to this library, there are three things to pay close attention to:- Check Your Shapes: When you multiply matrices, their dimensions must be compatible. Get into the habit of checking the
.shapeof your arrays to decide if you need the array or its transpose. - Know Your Axis: Many
numpyfunctions can operate along different dimensions (e.g., sum down a column vs. across a row). Double-check if the function should be onaxis=0,axis=1, etc. - Embrace Vectorization: Using
numpy's built-in functions on entire arrays (vectorization) is much, much faster than writing your ownforloops. It’s a cornerstone of efficient ML code in Python.
- Check Your Shapes: When you multiply matrices, their dimensions must be compatible. Get into the habit of checking the
5. How I Felt While Taking the Course
For me, taking this specialization was a joy. It served as an excellent refresher, and there is nothing like revisiting fundamentals to solidify your understanding. When you see a concept for the second time after having applied it in practice, you appreciate the details and nuances in a completely new way.
What I felt most strongly was a deep appreciation for the teaching itself. I truly enjoyed the progression of each slide. You can see the immense thought and effort that went into designing the learning path. It was inspiring to see a masterclass in pedagogy.
Reflecting on the material, I found that about 80% of it felt very familiar. However, the sections on Unsupervised Learning and Recommender Systems were more challenging, simply because I haven't used them extensively in my own projects. It was a reminder that there is always more to learn and that hands-on application is what truly cements knowledge. The difference between "I've seen this before" and "I've built this before" is very real.
6. Is This Specialization for You?

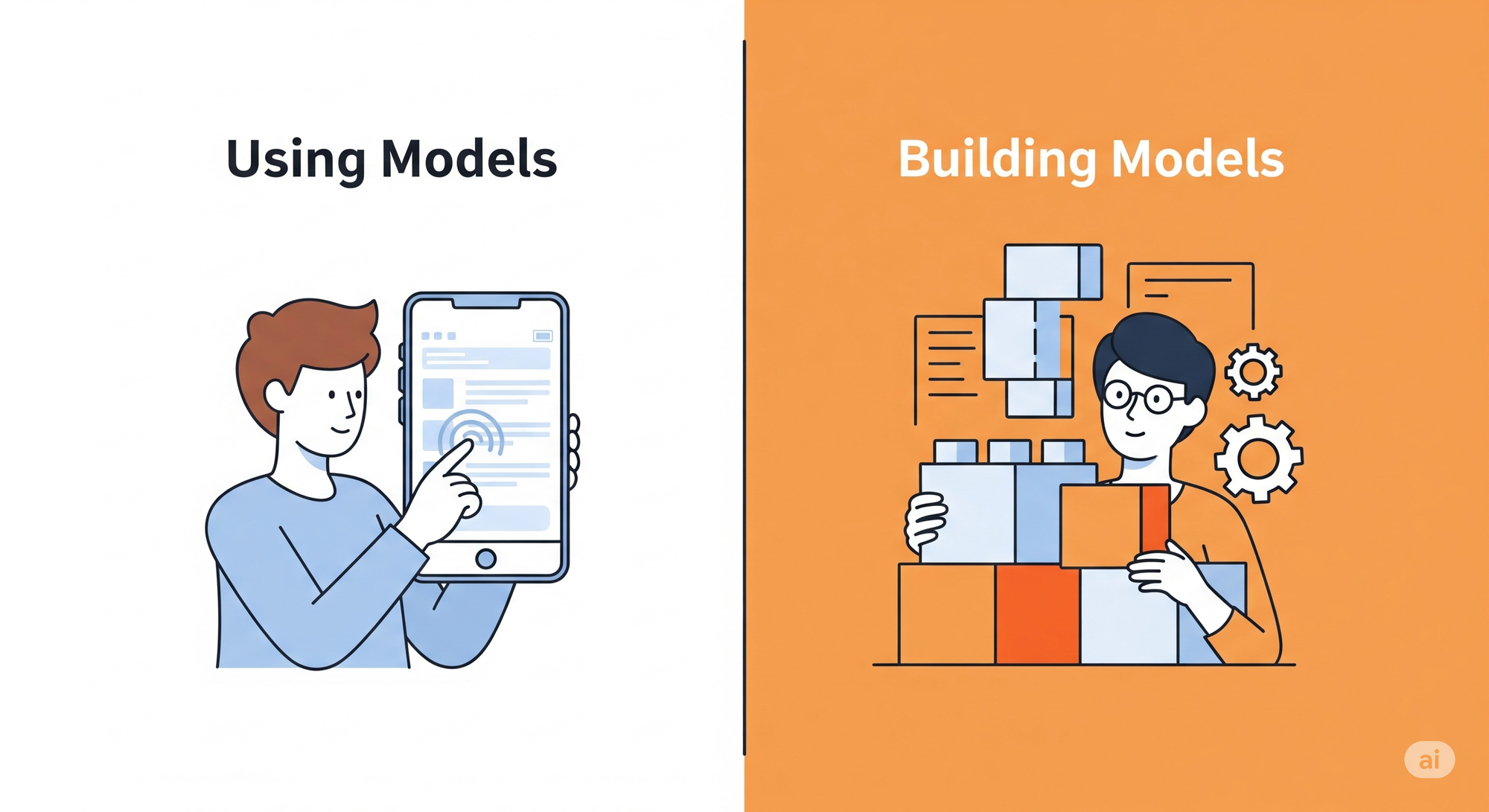
With the journey mapped out, the most important question remains: is this the right specialization for you? In today's world, this question comes down to a fundamental choice: do you want to use machine learning models, or do you want to build them?
You can create amazing applications today by using powerful, pre-trained models like LLMs through APIs or MCP servers. You can even fine-tune some of these models to better fit your needs. For many people, that is more than enough.
This specialization is for those who want to go deeper. It's for people who want to understand what is happening inside the black box. It teaches you how to create your own models for regression, classification, computer vision, and more. It gives you the foundational knowledge to diagnose a model that isn't working and the tools to fix it. On top of that, you learn the vocabulary used in Machine Learning.
Regarding the prerequisites, while the course has less rigorous math than the 2018 version, you should still have a "math mindset." The equations and notations might look intimidating at times, and managing indices in code requires a comfort with abstract thinking. You don't need to be a calculus expert, but if the sight of an equation makes you want to close the browser, this might be a challenge.
Finally, you must be ready to commit the time. The specialization is designed to be taken over 10 weeks, with an estimated 5 to 10 hours of work per week.
If you are ready for that commitment and excited by the idea of building models from the ground up, then I believe this is one of the best possible starting points available today.
7. How It Compares with the 2018 Course
For those familiar with Andrew Ng's original course, it's worth highlighting what makes this new specialization different and, in my opinion, a significant improvement.
- Python, Not Octave/MATLAB: This is the most important practical change. The entire specialization is taught in Python using standard libraries like NumPy and TensorFlow. This makes the skills you learn immediately applicable to modern AI development jobs and projects.
- More Intuition, Less Math: The 2018 course was great for building intuition, but this version is even better. It relies more on analogies and visual explanations to help you grasp the concepts before diving into the mathematical theory. The math is still there for those who want it, but it feels less like a hard requirement.
- Expanded and Modernized Topics: The curriculum now includes topics that are essential today but were not as prominent in the original, such as a deep dive into decision trees and a proper introduction to the TensorFlow framework. The advice on how to apply machine learning has also been thoroughly updated with best practices from the last decade.
- Improved Notation: While there are still a lot of mathematical symbols, the notation itself has been cleaned up and made more consistent, which makes it easier to follow.
A Final Thought
Starting with the simple building blocks of Y = WX + b, this specialization takes you on a journey through the most important areas of modern machine learning. You end up with a broad set of tools and, more importantly, a solid intuition for how and why they work.
Revisiting these fundamentals in such a well-crafted program was not only a pleasure but also affirmed my belief that for anyone serious about learning to build in this field, there is no better guide than Andrew Ng. I can now confidently recommend this path to my teammates, to others starting out, and maybe to you.
Thank you Andrew Ng for this great specialization.




